Gamesbeater with Reinforcement Learning
I found a video about the NEAT(NeuroEvolution of Augmenting Topologies) algorithm used to train agents, with reinforcement learning and genetic approaches, applied to playing super mario and thought it was really cool – MarI/O.
Some time later I had an assignment where the professor wanted us to write papers, so I used that as an excuse to try to build something like the MarI/O and try some cool algorithms.
Tools Selection
To be able to train and test agents who do stuff first an environment was needed. After searching and reading some papers about the state of the art, I found a cool environment for testing, the ALE (Arcade Learning Environment).
With this environment I can run Atari 2600 games, access each pixel in the monitor, each byte in RAM, the current score, I have access to the list of possible actions allowed like if we had the controller and the agent can use this actions to play the game.
Next to implement the agent and the learning I needed some reinforcement learning algorithms. After some search I found a nice library that had reinforcement learning pybrain.
Implementation
The first step was to launch the ALE environment and play as a human instead of using an agent, the first game was the good old breakout.
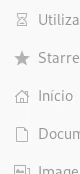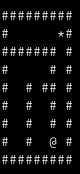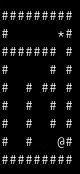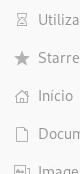
After some play, the next step was to try pybrain with some of their Reinforcement Learning examples. I tried the SARSA, Q Learning with their maze example, and trained my agents until they could leave different mazes, all with reinforcement learning.
Agent trying to leave the maze
With the ALE environment ready and the pybrain algorithms tested, the next point is the merging of both. Our neural network will use the ActionValueNetwork class from pybrain to hold the agent brain. This type of network will try to have weights directly mapped to specific actions.
Since I want the agent to play like a human, it will use only the actions available in the controller and can only see the monitor pixels like a human playing. This way the network will have as inputs the monitor pixels in rbg format and will map that to the controller possible actions.
For the learning method I will use Q Learning. The goal of Q-Learning is to learn a policy, which tells an agent which action to take under which circumstances.
With the pybrain and ALE joined now I can run the agents playing the game.
Before starting training them I want to be able to store the network if their train goes well, load a previous save network and I want a way to stop their traning at any moment.
For the saving and loading I used python pickle module which serializes a python object and stores in a file. To stop the training at any moment I used the curses module which allows me to listen for keyboard input in a non-blocking way, so when I press q the training stops and the current network is saved.
Since we are training the agents with reinforcement learning we will need a reward function to give them an heuristic to evaluate their actions. We can collect the score from the ALE, so we will use the current score in the game until the agent dies.
Now we have all the stuff setup so let’s check the progress of the agents with some training time.
Without training
After 2h of training
Result
We can observe that the bot without any train moves around very much because he is just trying random commands to control the player. While the bot with two hours of training is already going much more for the walls since he could understand the ball will hit there more.
Anyway after some more train the movement of the bot didn't improve very much. Some different approach to make it evolve was needed.
For the article I was writing, since I only tested already known algorithms and didn’t reach very good results I couldn’t really write a good paper about the implementation. So instead I made a review of the state of the art with the research I made about the topic. In the end I didn’t publish it but if you want to checkout the document – here.
I liked Pybrain, but it has some problems, it is still implemented in python2 and is not mantained since 2017. I sent them a pull request to fix one problem in an agent in 2018 and is still waiting. Their tutorial/examples do not work out of the box, some code needs to be changed to make them work. To make it work I had to try some stuff manually and go into their code to understand how it works.
Repository
If you want to use my setup to train some agents too, you can check the code in bitbucket
Other
If you want to receive updates when there are new games or development stories join the mailing list